
지난 3강까지 실습환경을 만들어 보았죠.
자 그럼 본격적으로 SQL 가지고 놀아봅시다.
실습을 위해서 PostgreSQL의 샘플 데이터베이스를 가져와서 설치하였습니다.
데이터베이스 생성, 테이블 생성 등은 다음에 알아보기로 하고
제일 기본이 되는 SELECT를 먼저 공부하도록 할게요.
먼저 명령을 실행할 도구인 HeidiSQL을 실행합니다.
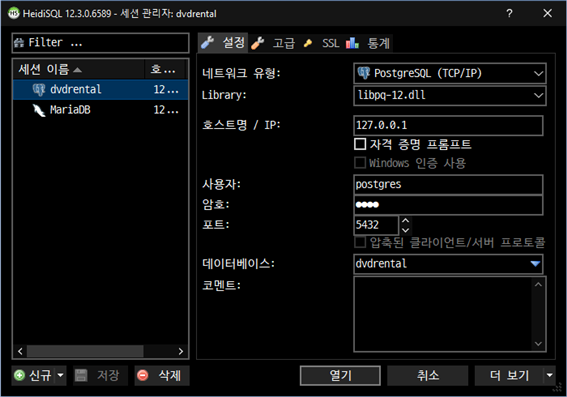
세션에서 dvdrental을 선택하고, 열기를 클릭

DBMS에 명령을 전달해줄 질의 도구가 실행되었습니다.
이제 HeidiSQL에서 명령을 전달하면 결과를 화면에 보여줍니다.
Tip) 화면 테마 변경은 메뉴에서 도구 – 환경설정 가셔서 마음에 드는 것으로 설정하시면됩니다.
지금부터 내려받은 DVD RENTAL ER DIAGRAM을 참조하시면서
실습에 사용되는 15개 테이블에 대해서 살펴보도록 하겠습니다.
프린터해서 보시면 좋을 것 같습니다. 별도창으로 보셔도 될 것 같고요.

HeidiSQL 왼쪽창 트리 목록에서 film을 클릭해 봅니다.
오른쪽 창에서 테이블:film 탭으로 가보면

film 테이블의 구성을 볼 수 있습니다.
이름(column, 열, 속성), 데이터유형, 길이/설정 등 테이블의 정보를 보실 수 있습니다.
데이터 탭에는 테이블의 전체 row(행, record, tuple)를 볼 수 있습니다.

film을 누르기만 했는데 정보가 나옵니다.
1. 트리에서 film을 누르기
2. HeidiSQL에서 SQL을 생성하여 DBMS에 전달
3. DBMS에서 온 결과를 사용자에게 보여줌
이런 순서로 진행되는 것입니다.
HeidiSQL이 중간에 없었다면 사용자는 명령 창을 통해 모든 것을 수작업으로 해야 하는 거죠.
쿼리 툴에 따라서 보여주는 방식이나 정보는 다릅니다.
그것은 쿼리툴을 만든 프로그래머가 다르게 프로그램했기 때문이겠죠.
이제 erd를 보면서 15개 테이블을 알아보도록 하겠습니다.
▶ actor – 이름과 성을 포함한 배우 데이터를 저장합니다.
▶ film – 제목, 개봉 연도, 길이, 등급 등의 필름 데이터를 저장합니다.
▶ film_actor – 영화와 배우 간의 관계를 저장합니다.
▶ category – 필름의 범주 데이터를 저장합니다.
▶ film_category- 필름과 범주 간의 관계를 저장합니다.
▶ store – 관리자 직원 및 주소를 포함한 상점 데이터를 포함합니다.
▶ inventory – 인벤토리 데이터를 저장합니다.
▶ rental – 렌탈 데이터를 저장합니다.
▶ payment – 고객의 결제를 저장합니다.
▶ staff – 직원 데이터를 저장합니다.
▶ customer – 고객 데이터를 저장합니다.
▶ address – 직원 및 고객의 주소 데이터를 저장합니다.
▶ city - 도시 이름을 저장합니다.
▶ country – 국가 이름을 저장합니다.
15개 테이블에 대해서 HeidiSQL에서 조회해서
어떤 컬럼들로 구성되어 있는지? 데이터는 어떻게 들어가 있는지?
스스로 공부해 보시기 바랍니다.
이제 본격적으로 SELECT QUERY를 실행해볼까요?
HeidiSQL 쿼리창에
▶ SQL문
SELECT first_name
FROM customer;
입력하고 실행(단축키 F9) 합니다.

결과 확인하셨나요?
; 은 SQL문의 끝을 알려주는 부호입니다. SQL문의 일부가 아닙니다.
쿼리창에
▶ SQL문
SELECT first_name
FROM customer;
SELECT first_name, last_name
FROM customer;
SELECT *
FROM customer;
입력하고 실행(F9)해보세요.
결과가 3개의 탭으로 나옵니다.
; 로 구분된 3개의 SQL 문이 실행된 것입니다.
*는 모든 열의 줄임말입니다. 모든 칼럼을 나열하는 대신에 *를 사용할 수 있습니다.
그러나 실제 프로젝트에서는 * 사용을 금지하는 곳이 대부분입니다.
테이블의 변경 – 칼럼 순서변경, 칼럼 추가 등으로 오류를 만들어냅니다.
여러분들이 실제 개발자로서 프로젝트에 참여한다면 *는 사용하지 마세요.
습관적으로 *를 사용하는 개발자들을 볼 수 있습니다.
가져온 데이터중에 단 1개의 컬럼만 사용하면서도 *를 남발합니다.
불필요한 데이터를 가져오면 데이터베이스 서버와 애플리케이션 서버 간의 트래픽이 증가합니다. 따라서 애플리케이션의 응답 속도가 느려지고 확장성이 저하될 수 있습니다.
HeidiSQL의 SQL 실행방법은 3가지
실행 F9
선택 실행 Ctrl+F9
현재 쿼리 실행 Shift+Ctrl+F9
3가지의 차이를 실습해보면서 알아보시기 바랍니다.
▶ SQL문
SELECT
first_name || ' ' || last_name,
FROM
customer;
를 입력하고 실행해보세요.
|| 는 연결 연산자입니다. customer 테이블에 개별로 저장된 이름을 붙여서 조회할 수 있습니다.
▶ SQL문
SELECT
concat(first_name, ' ', last_name),
FROM
customer;
|| 연결 연산자 대신에 concat 함수를 사용할 수도 있습니다.
▶ SQL문
SELECT 5 * 3;
FROM절이 생략된 SQL문 입니다.
오라클에서는 함수 등을 확인하기위한 SQL문에 DUAL이라는 DUMMY테이블을 사용합니다.
PostgreSQL에서는 FROM절을 생략해도 됩니다.
오라클, DB2 등에서
SELECT CURRENT_TIMESTAMP FROM DUAL;
사용했다면
PostgreSQL, MySQL, MariaDB 등 에서는 FROM절을 생략해야 합니다.
SELECT CURRENT_TIMESTAMP;
다음 시간에 만나요~~
'IT > SQL 기초강좌 (PostgreSQL)' 카테고리의 다른 글
| 6강 SQL이 뭐지? SELECT DISTINCT 뽀개기 (3) | 2022.12.13 |
|---|---|
| 5강 SQL이 뭐지? Column Aliases ORDER BY (4) | 2022.12.13 |
| 3강 SQL이 뭐지? 도구들을 설치해보자. ( PostgreSQL, HeidiSQL ) (17) | 2022.12.10 |
| 2강 SQL이 뭐지? (8) | 2022.12.10 |
| 1강 (프롤로그) SQL 배우고 싶니? 유료강좌 싸다구 때려주께 ~~ (11) | 2022.12.10 |




댓글