
PostgreSQL 기초강의, PostgreSQL 기초강좌, CUME_DIST
86강 SQL 함수 정리 : PostgreSQL CUME_DIST Function
SQL 함수 정리 86강 시작합니다.
이번 시간에는
▶ PostgreSQL CUME_DIST Function
에 대해서 알아보는 시간입니다.
이번 시간에는 PostgreSQL CUME_DIST() 함수를 사용하여 값 집합 내에서 값의 누적 분포를 계산하는 방법에 대해 알아봅니다.
PostgreSQL CUME_DIST() 함수 개요
경우에 따라 데이터 세트의 상위 또는 하위 x% 값(예: 매출 기준 상위 1% 제품)을 표시하는 보고서를 생성할 수도 있습니다.
CUME_DIST() 함수는 값 집합 내에서 값의 누적 분포를 반환합니다. 즉, 값 집합에서 값의 상대적 위치를 반환합니다. 오름차순을 가정했을 때 누적 분포는 다음과 같은 공식으로 결정됩니다.
count of rows with values / count of rows in the window or partition
값이 있는 행의 순위 / 창 또는 파티션의 행 수
CUME_DIST() 함수의 구문은 다음과 같습니다:
CUME_DIST() OVER (
[PARTITION BY partition_expression,... ]
ORDER BY sort_expression [ASC | DESC],...
)
이 구문에서:
PARTITION BY clause
PARTITION BY 절은 행을 함수가 적용되는 여러 파티션으로 나눕니다.
PARTITION BY 절은 선택 사항입니다. 이를 건너뛰면 CUME_DIST() 함수가 전체 결과 집합을 단일 파티션으로 처리합니다.
ORDER BY clause
ORDER BY 절은 CUME_DIST() 함수가 적용되는 각 파티션의 행을 정렬합니다.
Return value
CUME_DIST()는 0보다 크고 1보다 작거나 같은 double precision(부동소수점 숫자) 값입니다:
0 < CUME_DIST() <= 1
함수는 동일한 값에 대해 동일한 누적 분포 값을 반환합니다.
PostgreSQL CUME_DIST() 예제
먼저 직원별 판매 수익을 저장하는 sales_stats라는 새 테이블을 만듭니다:
CREATE TABLE sales_stats(
name VARCHAR(100) NOT NULL,
year SMALLINT NOT NULL CHECK (year > 0),
amount DECIMAL(10,2) CHECK (amount >= 0),
PRIMARY KEY (name, year)
);
둘째, sales_stats 테이블에 몇 개의 행을 삽입합니다:
INSERT INTO
sales_stats(name, year, amount)
VALUES
('John Doe',2018,120000),
('Jane Doe',2018,110000),
('Jack Daniel',2018,150000),
('Yin Yang',2018,30000),
('Stephane Heady',2018,200000),
('John Doe',2019,150000),
('Jane Doe',2019,130000),
('Jack Daniel',2019,180000),
('Yin Yang',2019,25000),
('Stephane Heady',2019,270000);
다음 예제는 CUME_DIST() 함수를 더 잘 이해하는 데 도움이 됩니다.
1) 결과 집합 예제에서 PostgreSQL CUME_DIST() 함수 사용
다음 예제에서는 2018년 각 영업 사원의 매출액 백분위수를 반환합니다:
SELECT
name,
year,
amount,
CUME_DIST() OVER (
ORDER BY amount
)
FROM
sales_stats
WHERE
year = 2018;
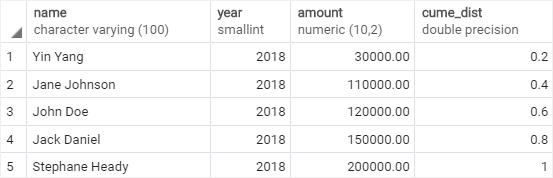
누적분포는 1/5, 2/5, 3/5, 4/5, 5/5 입니다.
2) 파티션 예제에서 PostgreSQL CUME_DIST() 함수 사용
다음 예제에서는 CUME_DIST() 함수를 사용하여 2018년과 2019년 각 영업 사원의 매출 백분위수를 계산합니다.
SELECT
name,
year,
amount,
CUME_DIST() OVER (
PARTITION BY year
ORDER BY amount
)
FROM
sales_stats;
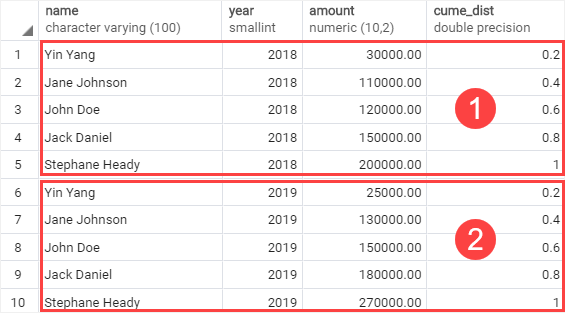
위 예에서는 다음을 수행합니다:
- PARTITION BY 조항은 2018년과 2019년까지 행을 두 개의 파티션으로 나누었다.
- ORDER BY 절은 CUME_DIST() 기능이 적용된 각 파티션의 모든 직원의 매출액을 높음부터 낮음까지 정렬했습니다.
이번 강의에서는 PostgreSQL CUME_DIST() 함수를 사용하여 값 그룹에서 값의 누적 분포를 계산하는 방법에 대해 배웠습니다.
감사합니다.
| 본 강의는 PostgreSQL Tutorial을 참조합니다. https://www.postgresqltutorial.com/ |
| Do it! SQL을 찾아 주셔서 감사합니다. 공감 ♥ , 댓글이 큰 힘이 됩니다. |
'IT > SQL 기초강좌 (PostgreSQL)' 카테고리의 다른 글
| 88강 SQL 함수 정리 : PostgreSQL FIRST_VALUE Function (58) | 2023.01.30 |
|---|---|
| 87강 SQL 함수 정리 : PostgreSQL PERCENT_RANK Function (117) | 2023.01.29 |
| 85강 SQL 함수 정리 : PostgreSQL DENSE_RANK Function (106) | 2023.01.27 |
| 84강 SQL 함수 정리 : PostgreSQL RANK Function (97) | 2023.01.26 |
| 83강 SQL 함수 정리 : PostgreSQL ROW_NUMBER Function (149) | 2023.01.26 |




댓글